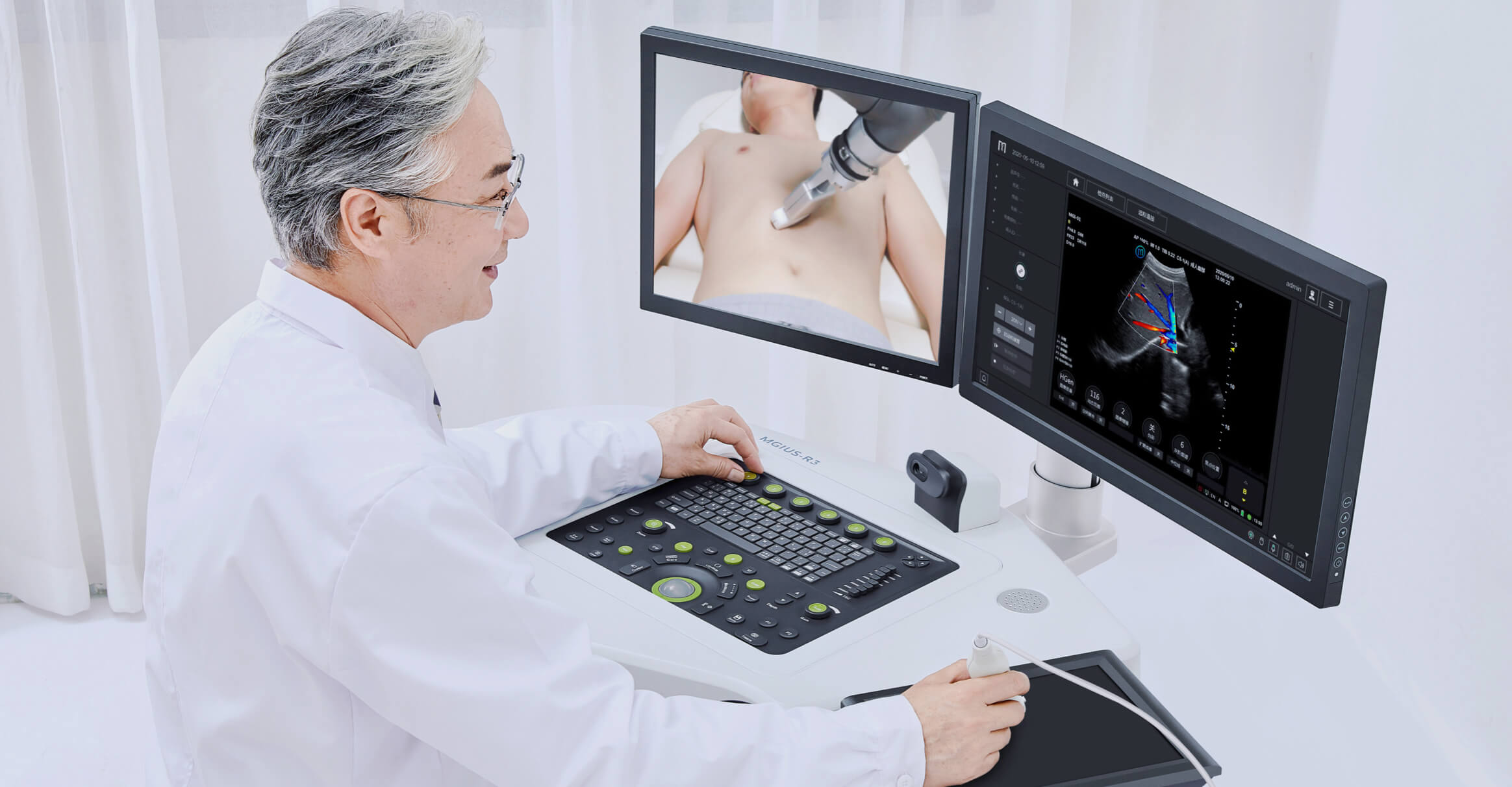
About MGI
MGI Tech Co., Ltd. (or its subsidiaries, together referred to MGI), is committed to building core tools and technologies that drive innovation in life science. Our focus lies in research & development, manufacturing, and sales of instruments, reagents, and related products in the field of life science and biotechnology. We provide real-time, multi-omics, and full spectrum of digital equipment and systems for precision medicine, agriculture, healthcare and various other industries.
 Sequencer Products: SEQ ALL
Sequencer Products: SEQ ALL Technologies
Technologies Applications
Applications Online Resources
Online Resources Data Bulletins
Data Bulletins Service & Support
Service & Support Introduction
Introduction Newsroom
Newsroom Doing Business With Us
Doing Business With Us Creative Club
Creative Club